

作者 | Java发财责编 | 王晓曼出品 | CSDN博客送分题面试官:有操作过Linux吗?我:有的呀。面试官:我想查看内存的使用情况该用什么命令?我:Free 或者 Top。面试官:那你说一下用free命令都可以看到啥...

作者 | Java发财
责编 | 王晓曼
出品 | CSDN博客

送分题
面试官:有操作过Linux吗?
我:有的呀。
面试官:我想查看内存的使用情况该用什么命令?
我:Free 或者 Top。
面试官:那你说一下用free命令都可以看到啥信息
我:如下图所示 可以看到内存以及缓存的使用情况:
total总内存
used已用内存
free空闲内存
buff/cache已使用的缓存
avaiable可用内存

面试官:那你知道怎么清理已使用的缓存吗(buff/cache)?
我:em… 不知道。
面试官:sync; echo 3 > /proc/sys/vm/drop_caches就可以清理buff/cache了,你说说我在线上执行这条命令做好不好?

我:(送分题,内心大喜)好处大大的有,清理出缓存我们就有更多可用的内存空间, 就跟pc上面xx卫士的小火箭一样,点一下,就释放出好多的内存。
面试官:em…., 回去等通知吧。

SQL Join
面试官:换个话题,谈谈你对Join的理解。
我:好的(再答错就彻底完了,把握住机会)
回顾:
SQL 中的 Join 可以根据某些条件把指定的表给结合起来并将数据返回给客户端。
Join的方式有:
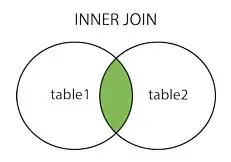
1、innerjoin 内连接
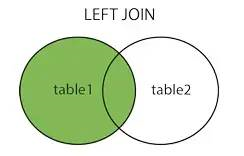
2、leftjoin 左连接
3、rightjoin 右连接
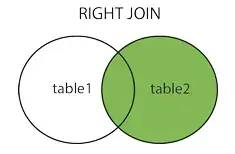
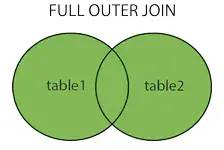
4、fulljoin 全连接
面试官:在项目开发中如果需要使用 Join 语句,如何优化提升性能?
我:分为两种情况,数据规模小的,数据规模大的。
面试官: 然后?
我:对于:
1.数据规模较小,全部放进内存就完事了。
2.数据规模较大:
可以通过增加索引来优化 Join 语句的执行速度。
可以通过冗余信息来减少 Join 的次数。
尽量减少表连接的次数,一个 SQL 语句表连接的次数不要超过5次。
面试官:可以总结为 Join 语句是相对比较耗费性能,对吗?
我:是的。
面试官: 为什么?

缓冲区
我: 在执行 Join 语句的时候必然要有一个比较的过程。
面试官: 是的。
我:逐条比较两个表的语句是比较慢的,因此我们可以把两个表中数据依次读进一个内存块中, 以 MySQL的InnoDB 引擎为例,使用以下语句我们必然可以查到相关的内存区域 show variables like ‘%buffer%’
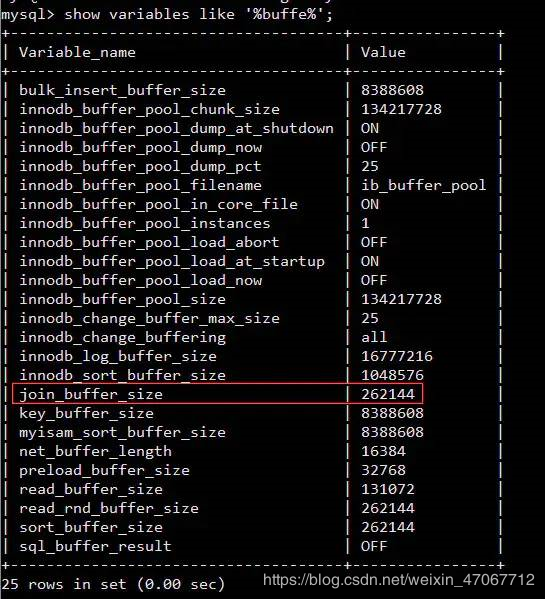
如图所示 Join_buffer_size的大小将会影响我们 Join 语句的执行性能。
面试官: 除此之外呢?
一个大前提
我:任何项目终究要上线,不可避免的要产生数据,数据的规模又不可能太小。
面试官: 是这样的。
我:大部分数据库中的数据最终要保存到硬盘上,并且以文件的形式进行存储。
以 MySQL的 InnoDB 引擎为例
InnoDB 以页(page)为基本的IO单位,每个页的大小为16KB, InnoDB 会为每个表创建用于存储数据的 .ibd 文件。
验证:
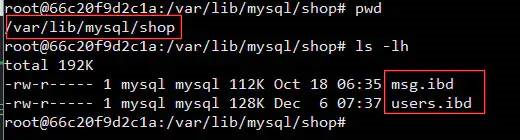
我:这意味着我们有多少表要连接就需要读多少个文件,虽然可以利用索引,但还是免不了频繁的移动硬盘的磁头。
面试官:也就是说频繁的移动磁头会影响性能对吧?
我:是的,现在的开源框架不都喜欢说自己通过顺序读写大大的提升了性能吗,比如 hbase、kafka。
面试官:说的没错,那你认为 Linux 有对此做出优化吗?提示,你可以再执行一次 Free 命令看一下。
我:奇怪缓存怎么占用了1.2G多?

面试官:你有没有想过?buff/cache 里面存的是什么?为什么 buff/cache 占了那么多内存,可用内存即 availlable 还有1.1G?为什么你可以通过两条命令来清理 buff/cache 占用的内存,而想要释放used只能通过结束进程来实现?
品,你细品。
思考了几分钟后。
我:这么随便就释放了 buff/cache 所占用的内存,说明它就不重要, 清除它不会对系统的运行造成影响
面试官: 不完全对。
我:难道是?想起来《CSAPP》(深入理解计算机系统)里面说过一句话:存储器层次结构的本质是,每一层存储设备都是较低一层设备的缓存。
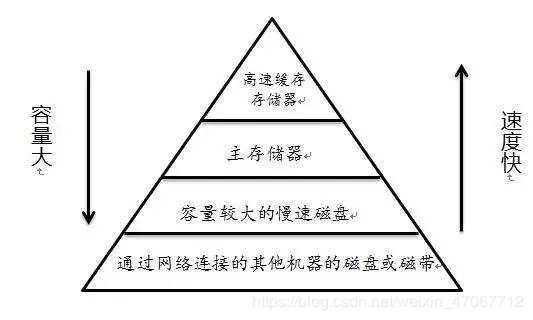
通俗来说,就是说 Linux 会把内存当作是硬盘的高速缓存。
面试官:现在知道那道送分题应该怎么回答了吧。
我:我….

Join算法
面试官:再给你个机会,如果让你来实现 Join 算法你会怎么做?
我:无索引的话,嵌套循环就完事了嗷。有索引的话,则可以利用索引来提升性能。
面试官:说回 Join_buffer 你认为 Join_buffer 里面存储的是什么?
我:在扫描过程中,数据库会选择一个表把他要返回以及需要进行和其他表进行比较的数据放进 Join_buffer。
面试官:有索引的情况下是怎么处理的?
我:这个就比较简单了,直接读取两个表的索引树进行比较就完事了,我这边介绍一下无索引的处理方式:
1、NestedLoop Join
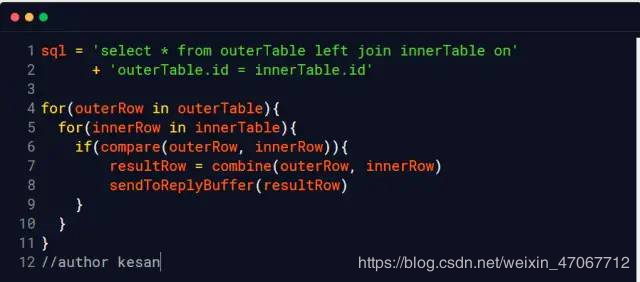
嵌套循环,每次只读取表中的一行数据,也就是说如果 outerTable有10万行数据, innerTable 有100行数据,需要读取10000000次(假设这两个表的文件没有被操作系统给缓存到内存, 我们称之为冷数据表)。
当然现在没啥数据库引擎使用这种算法(太慢了)。
2、Blocknested loop
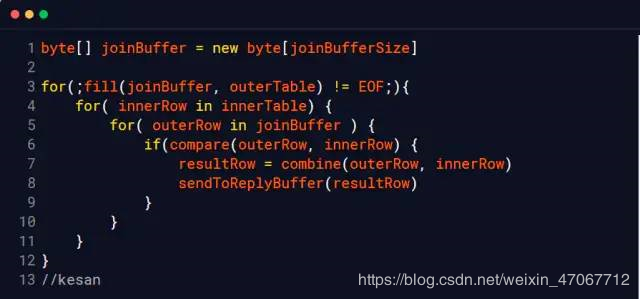
Block块,也就是说每次都会取一块数据到内存以减少I/O的开销。
当没有索引可以使用的时候,MySQL InnoDB 就会使用这种算法。
考虑以下两个表 t_a 和t_b:
当无法使用索引执行 Join 操作的时候,InnoDB 会自动使用Block nested loop 算法。

上学时,数据库老师最喜欢考数据库范式,直到上班才学会一切以性能为准,能冗余就冗余,实在冗余不了的就 Join 如果 Join 真的影响到性能。试着调大你的 Join_buffer_size , 或者换固态硬盘。
版权声明:本文为CSDN博主「Java发财」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_47067712/article/details/105972620
来源:本文内容搜集或转自各大网络平台,并已注明来源、出处,如果转载侵犯您的版权或非授权发布,请联系小编,我们会及时审核处理。
声明:江苏教育黄页对文中观点保持中立,对所包含内容的准确性、可靠性或者完整性不提供任何明示或暗示的保证,不对文章观点负责,仅作分享之用,文章版权及插图属于原作者。






全国统一热线: 025-81550000
地址:中国●江苏 南京市秦淮区洪武路359号1506室
邮箱:service#改成@jsedu114.com

微信公众号

新浪微博
暂不支持手机端,请登录电脑端访问