

DeepSeek是一款无需魔法、零代码、消费级显卡畅玩的推理型人工智能工具。它具有媲美GPT-4o32B版本的推理能力,以及接近GPT-4 Turbo全链路的国产化部署。
无需魔法|零代码|消费级显卡畅玩
为什么选择DeepSeek?
| 优势 | 详解 |
|---|---|
| 媲美GPT-4o | |
| 全链路国产 | |
| 极简部署 | |
| 全规格覆盖 | |
| 经济高效 |
硬件配置指南(消费级设备推荐)
| 7B | ||||
| 14B | ||||
| 32B |
实测:RTX 3090可丝滑运行30B模型
三步极速部署(Windows版)
相关的软件,我已经放入到网盘,网不好的同学,可以直接下载。 下载链接:https://pan.quark.cn/s/b69829720b68
部署架构
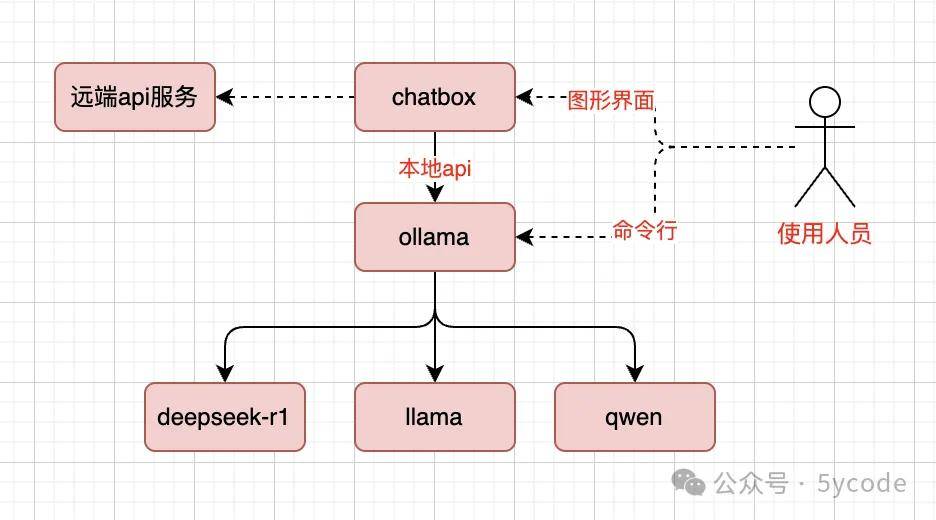
ollama 安装
Ollama 是一个专注于本地化部署和运行大型语言模型(LLM)的工具,旨在让用户能够在自己的设备上高效地运行和微调模型。
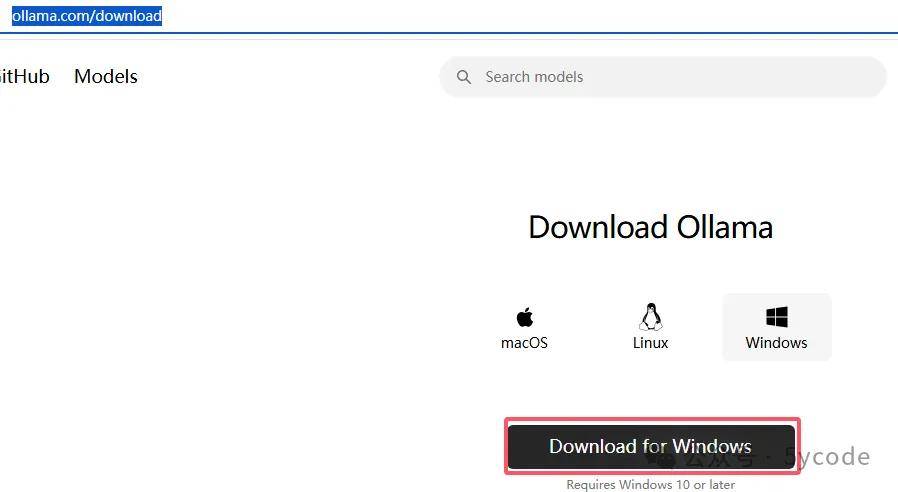
下载ollama
https://ollama.com/download/ 默认为当前电脑的对应的版本,直接下载即可。下载以后,一路点点点即可。
环境变量设置安装完以后先不要使用,先设置下环境变量。默认模型下载到C盘。一个模型最小也得几个GB 。

OLLAMA_HOST: 0.0.0.0
OLLAMA_MODELS:E:\ai\ollama\models
OLLAMA_HOST:设置为0.0.0.1 会将ollama服务暴露到所有的网络,默认ollama只绑定到了127.0.0.1和localhost上了。 OLLAMA_MODELS:设置了模型的存放的地址。

验证
PS C:\Users\yxkong> ollama -v
ollama version is 0.4.0
ollama常用操作命令
#下载模型
ollama pull 模型名称
ollama pull deepseek-r1:32b
#运行模型,如果模型不存在,则下载
ollama run 模型名称
ollama run deepseek-r1:32b
#查看已下载的模型
ollama list
#删除本地已下载的模型
ollama rm 模型名称
#查看模型的详细信息
ollama show 模型名称
deepseek-r1安装
https://ollama.com/search 打开ollama官网,点击Models,可以搜索,目前deepseek最流行,排到了第一位。
除了671是真正的deepseek,其他的都是蒸馏的模型。
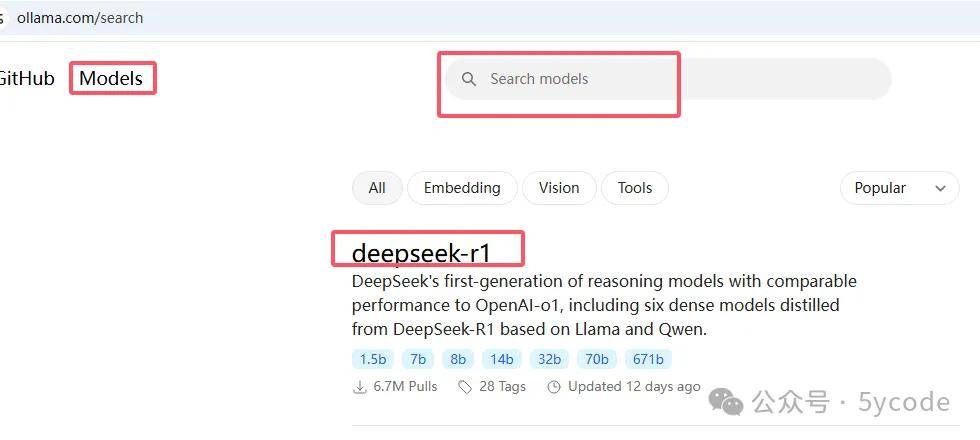
根据自己电脑的配置选择对应规格的模型,然后复制对应的命令即可。
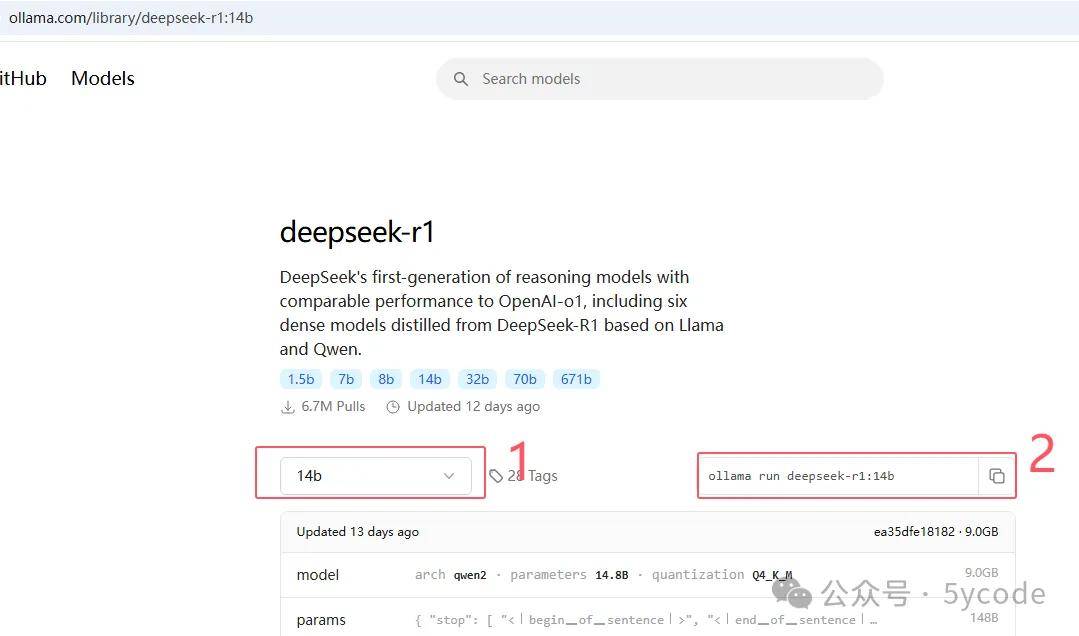
ollama run deepseek-r1:32b

慢慢等待即可。运行效果8b的模型凑合能用、14b的模型基本能用,32b的模型使用很是顺滑。 至此,deepseek的本地部署已经完成。

chatbox
Chatbox 是一个开源的聊天界面工具,专门为大型语言模型(如 GPT、LLaMA 等)设计,提供用户友好的交互界面。
使用chatbox的优势
交互简单
预设prompt(我的搭档)
自定义模型服务方
独立代理
下载
下载以后一路点点点即可。
环境配置
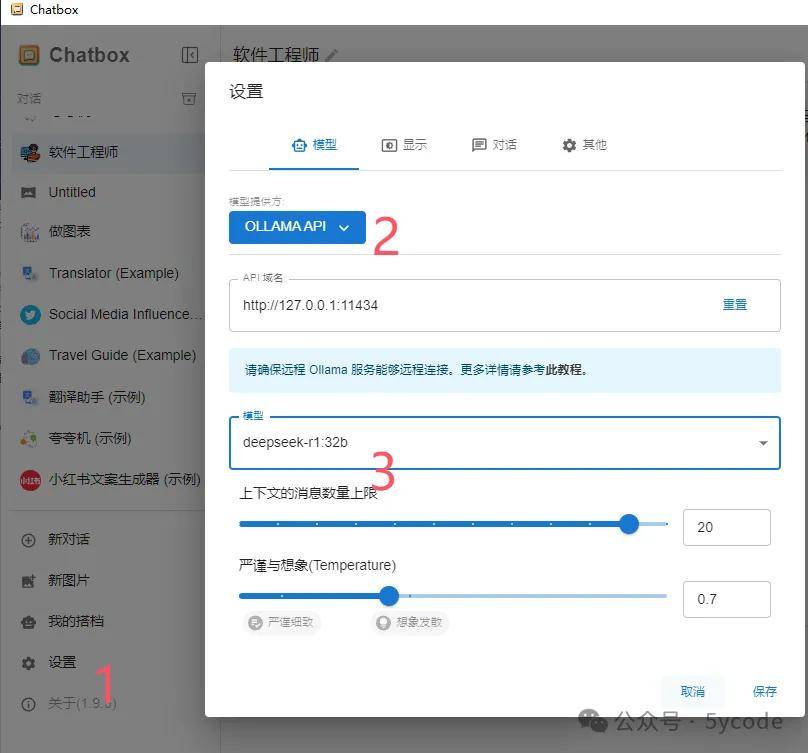
点击设置
选择模型提供方
选择模型(本机地址默认即可)
测试

很是顺滑
性能加速方案(Ollama专用)
| 量化加速 | deepseek-r1:32b-q4_0模型 | ||
| 多GPU支持 | CUDA_VISIBLE_DEVICES | ||
| 内存优化 | OLLAMA_MAX_MEMORY参数 |
实操命令示例
# 使用量化模型(需先下载)
ollama run 模型-q4_0
# 多GPU支持(指定使用GPU 0和1)
ollama run deepseek-r1:32b
交互优化技巧
界面增强方案
| Markdown渲染 | \n请用markdown格式回答 |
| 对话流控制 | /retry重新生成回答 /forget清除对话历史 |
| 语音输入 | |
| 快捷键体系 |
高级交互配置
# 创建~/.ollama/config.yaml
system_prompt: "你是一个精通科技知识的助手,回答请简明扼要,使用中文口语化表达"
temperature: 0.7 # 控制创造性(0-1)
max_length: 4096 # 最大生成长度
常见问题解决方案
OLLAMA_NUM_THREADS=8 | ||
/continue继续生成 | ||
/forget清除上下文 |
后记
个人小助手已经搭建完成,大家的工作、生活问题尽情的问吧,不联网,隐私。大家可以关注下,后续基于deepseek我再搭建个知识库分享给大家。
原文来源:https://mp.weixin.qq.com/s?__biz=MjM5NzQxMTAyNw==&mid=2247485191&idx=1&sn=6590bae7fb960a2577c2b77c11479080&scene=21#wechat_redirect
来源:本文内容搜集或转自各大网络平台,并已注明来源、出处,如果转载侵犯您的版权或非授权发布,请联系小编,我们会及时审核处理。
声明:江苏教育黄页对文中观点保持中立,对所包含内容的准确性、可靠性或者完整性不提供任何明示或暗示的保证,不对文章观点负责,仅作分享之用,文章版权及插图属于原作者。






全国统一热线: 025-81550000
地址:中国●江苏 南京市秦淮区洪武路359号1506室
邮箱:service#改成@jsedu114.com

微信公众号

新浪微博
暂不支持手机端,请登录电脑端访问